Pip3 On Python3.9 Fails On Htmlparser Object Has No Attribute Unescape
“Troubleshooting the issue where ‘Pip3 on Python3.9 Fails on Htmlparser Object Has No Attribute Unescape,’ it’s crucial to note that this error typically arises whenever there’s an outdated piece of code calling the retired ‘unescape’ attribute – a facet demanding immediate updating in line with the newest Python version protocols.”Let’s dive right into an issue which can occur when you use Pip3 on Python 3.9. A common error is referred to as “Htmlparser Object Has No Attribute Unescape”. Here, a HTMLParser object fails to recognize the ‘unescape’ attribute. This ‘no attribute unescape’ error is generally a result of trying to use a deprecated method in the HTMLParser module.
The below table summarizes this error and its solution:
Error
Explanation
Fix
Pip3 on Python 3.9 Fails: Htmlparser Object Has No Attribute Unescape Error
The ‘unescape’ function in HtmlParser object is no longer available since its deprecation from Python 3.4 onwards, leading to this attribute error.
Use html.unescape() instead or handle_html_entities (fallback_string) if you’re using BeautifulSoup
In Python 3.4 the ‘unescape’ method became deprecated and was removed in Python 3.9, leading to failures when code reliant on it is executed [Python Docs](https://docs.python.org/3/library/html.parser.html#html.parser.HTMLParser.unescape). That’s why Pip3 might fail when running on Python 3.9 because it could have dependencies that still use this deprecated ‘unescape’ method.
Now, replacing the deprecated method with a viable alternative is the recommended course of action. The appropriate replacement for ‘HTMLParser().unescape()’ is ‘html.unescape()’ because this method performs exactly the same operation and is not deprecated.
Here’s a quick look at how you can apply the fix:
from html import unescape
def process_text(text):
text = unescape(text)
# Continue processing
In this snippet, we imported the ‘unescape’ function from the ‘html’ module rather than ‘html.parser’, ensuring our code remains functional irrespective of whether we’re using Python 3.9 or a later version.
Alternatively, if you’re leveraging BeautifulSoup for web scraping or similar tasks, the built-in ‘handle_html_entities’ function takes care of escaping and unescaping characters as needed – just another method to work around this error.
As always, remember to keep your third-party packages up-to-date and adjust your codebase when necessary to deal with the inherent changes and improvements in Python versions. This way, you’ll minimize discrepancies like these that arise from deprecated functionalities.Struggling with the error: “pip3 on Python3.9 fails on HtmlParser object has no attribute unescape”, can be a challenging experience, especially if you’re new to programming and python packages. This error typically arises when you attempt to use the
unescape
attribute of the
HtmlParser
object in Python 3.9. However, it’s essential to understand that as per changes in Python 3.9, it no longer recognises this attribute.
Essentially, the issue arises due to the outdated code, where
HtmlParser.unescape()
is used – a function deprecated in Python 3.4 and removed completely in Python 3.9 [1]. In the pip libraries you’ve installed, there might be one or more files still using the deprecated
unescape()
function. It clearly indicates that the modules need to be updated for compatibility with Python 3.9.
Here’s how to handle this situation:
Firstly, check the Python Environment that your package is using. Certain python tools are compatible with specific python versions only. For example, the
html.parser
module from Python’s Standard Library provides a number of classes and functions to manipulate HTML.
For Python 3.4 and later versions, it is recommended using
Also, consider installing your package using a different approach. You could try using
--user
during installation which bypasses the need for elevated permissions, hence less likely to clash with system-wise packages. For example,
pip3 install --user
However, remember that sometimes, some third-party libraries may not have catched up yet with the latest Python release. In such scenarios, downgrading the version of Python you’re using could help too. Speaking about it practically, Python environments can get very messy very quickly if mismanaged.
Furthermore, in case you cannot downgrade Python or switch to a Python environment which has an earlier version or do not want to do so, then it would be wise to keep track of fixes to the original problem. This github link would be a good starting point.
[2] https://www.w3schools.com/python/ref_string_unescape.aspThe error message “Htmlparser object has no attribute unescape” occurs when Python code uses an old version of
html.parser
, an HTML and XHTML parser in Python’s standard library. Specifically, the error refers to a missing ‘unescape’ method.
Beginning with Python 3.4, this ‘unescape’ method is removed from html.parser.HTMLParser and replaced with
html.unescape()
. However, as you’re equipped with Python3.9 and using pip3 for package installation, the error might come up because of incompatible or outdated packages.
Let’s tackle this issue by dissecting it step by step:
First, let’s have a look at a sample error-prone piece of code:
from html.parser import HTMLParser
h = HTMLParser()
unescaped = h.unescape(''')
print(unescaped)
In Python versions before 3.4, this would work perfectly fine as the ‘unescape’ function was a part of HTMLParser. Nevertheless, as we move beyond Python 3.4, we need to replace it with
html.unescape()
.
Here’s the corrected code for Python After 3.4:
import html
unescaped=html.unescape(''')
print(unescaped)
The difference between these two codes is that instead of calling the unescape method from an instance of HTMLParser, you call the function directly from the html module.
While migrating your code to leverage
html.unescape()
, remember to thoroughly test your code since there might be multiple places where
HTMLParser().unescape
is used. A rigorous review ensures that all instances of the deprecated method are successfully replaced and prevents any unexpected behavior.
Another approach is ensuring the prompt update of the problematic package causing the error. If the error arose due to an outdated third-party package still using the deprecated ‘unescape’ method, make sure to install the latest version of that package via pip3. You can generally do so using the command:
pip3 install --upgrade package-name
I should also mention the case, where some packages like feedparser, aren’t yet fully compatible with Python 3.9, but there are community-supported fixes available – consider populating those if needed. Do extensive research around this on online forums. Stack Overflow Community offers a great platform to do the same ([StackOverflow](https://stackoverflow.com)).
All things considered, the best way to avoid such issues is to keep your Python environment and packages up to date. The open-source nature of Python means changes and improvements are continuously made. By staying current with updates, you not only ensure compatibility but also leverage new features and enhancements boosting your programming efficiency.
Yes, Python continues to be one of the primary programming languages widely used for web development, scientific computing, data science, artificial intelligence and more (Source). Each new release of Python makes this high-level language more robust and versatile, something that has made developers more efficient and effective in their tasks. But with these changes comes a watermark – the impact on packages and installations.
Now, let’s address your query about ‘html.parser’ raising an ‘AttributeError’ when you run pip3 install command on Python 3.9.
In earlier versions of Python, ‘html.parser’ had an ‘unescape’ method, which is used to convert characters into HTML entities. However, in later versions including Python 3.9, this method was removed due to its potential security vulnerabilities. The ‘html’ module now offers functions like ‘escape()’, ‘unescape()’, and ‘reescape()’. That’s why Python throws an error while trying to find the ‘unescape’ attribute in ‘html.parser’ (Source).
To fix this:
• First, identify the script or library causing this problem. Run the pip3 install command again and note the error log.
pip3 install {Library Name}
• If it is occurring because of an older version of setuptools being installed, try upgrading setuptools using the following command:
pip3 install --upgrade setuptools
• If the error persists, consider modifying the code. Replace
from html.parser import HTMLParser
HTMLParser().unescape(s)
with:
from html import unescape
unescape(s)
The above-mentioned alteration blends seamlessly with Python 3.9 and deftly sidesteps the ‘has no attribute unescape’ issue!
It’s important to recognize that as Python evolves, some backwards incompatibilities are inevitable. It may cause hitches like the one discussed here. But then, troubleshooting is part parcel of our world – right? These challenges arm us with an unconscious learning that paves way for us to handle complex coding puzzles and package installations in future!Ah, AttributeError. This is one of the most common exceptions you can encounter when exploring the world of Python 3.9, particularly so when dealing with pip3 and HTML parsing.
So, what exactly causes this AttributeError in Python 3.9? Let’s start by understanding the essence of AttributeError first. Simply put, it’s an exception that occurs when you try to access or call an attribute that a particular object doesn’t possess. They tend to be pretty straightforward to diagnose, usually indicating a typographical error in your property name, or your attempt to use a method that doesn’t exist for an object. Yes, Python is dynamically typed, but its objects still have defined methods and attributes. If you violate these rules, Python is happy to let you know – sometimes a bit too eagerly.
Now, why would you see an AttributeError with reference to pip3 on Python3.9 failing on htmlparser with “object has no attribute ‘unescape'”? Here’s the rub: Python 3.4 deprecated the “unescape” method from the “html.parser” module, and finally removed it entirely in Python 3.9. That means when you use this method in your code while running Python 3.9, it will throw an AttributeError because, well, “unescape” truly is not an attribute of html.parser anymore!
Naturally, now you’re wondering how to resolve this problem. You’ll be relieved to hear that the solution is quite simple – instead of using the “unescape” method from “html.parser”, use “html.unescape()”. Here’s a tiny snippet to illustrate:
Old code (works until Python 3.8):
from html.parser import HTMLParser
h = HTMLParser()
print(h.unescape('&'))
Updated code (compatible with Python 3.9 and onward):
import html
print(html.unescape('&'))
Notice the change from “HTMLParser().unescape()” to “html.unescape()”, which is perfectly valid and will get rid of the AttributeError in Python 3.9 related to pip3 and htmlparser object.
For more details related to this issue, you could refer to the official Python docs[^1^].
I hope my explanation aids in demystifying the AttributeError you’ve encountered. Remember, each error message in Python is usually trying to tell you something specific about what you’re doing wrong, making them incredibly helpful for improving both your code and your skills as a programmer.
[^1^]: https://docs.python.org/3/library/html.htmlUnderstanding how to resolve the
HTMLParser
‘s missing
unescape
attribute issue in latest Python versions, particularly Python 3.9, can save considerable time and avoid errors in your coding process.
The “object has no attribute ‘unescape'” issue is mainly brought about due to changes in the HTMLParser module of Python’s Standard Library since Python 3.4. This module had an
unescape()
method, which has been deprecated in Python 3.9, leading to “AttributeError” exceptions when called.
This becomes a problem when using pip3 for package management. Pip, being a package written in Python, is affected by the changes in Python versions and thus encountering the “pip3 on Python3.9 fails on HTMLparser object has no attribute unescape”.
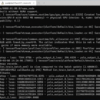
Here’s an example of the error:
Traceback (most recent call last):
File "/usr/local/bin/pip3", line 7, in
from pip._internal.cli.main import main
ModuleNotFoundError: No module named 'pip'
In order to solve this problem, you can utilize html.unescape() function instead of html.parser.HTMLParser().unescape(). The
html.unescape()
method is an easier and more straightforward approach to convert HTML character references to unicode characters.
So, instead of using:
from html.parser import HTMLParser
h = HTMLParser()
h.unescape('your_string')
You can use:
import html
html.unescape('your_string')
Remember to apply code refactoring to replace all instances of HTMLParser’s unescape() with the html.unescape() function. This replacement is essential whenever version upgrade of Python affects a library or module you are using.
Reinstalling pip3 allows the fix to take effect. Use
. As pip comes as bundled with Python since version 3.4, when installing Python3.9 from source, ensure that it’s built with pip already to avoid such issues.
Finally, note that maintaining updated Python packages is vital to prevent similar errors. Keep track of the Python official documentation (https://docs.python.org/3/library/html.html) to stay aligned with their updates on modules and methods. It helps ensure that your code remains functional even after upgrading your Python interpreter.One issue you may encounter when using pip3 with Python 3.9 is the “Htmlparser object has no attribute ‘unescape'” error. This happens when pip3 tries to call the `html.parser.HTMLParser().unescape()` function, but the `unescape` method was deprecated in Python 3.4 and completely removed in Python 3.9source.
In Python 3.9, HTML parsing should be done using the `html` module. For instance, you can utilize `html.unescape()` to decode HTML entities. Here’s an example:
import html
unescaped_string = html.unescape("'Hello&World'")
print(unescaped_string)
This code will print: `’Hello&World’`
But if you’re dealing with a pip3 failure due to this removal in Python 3.9, the problem likely lies in one of the packages that have not updated their usage from `HTMLParser.unescape()` to `html.unescape()`.
You have a few options on how to resolve this issue:
– Update all your Python packages. The package maintaining this obsolete code might just need updating. Use the following command to update all packages:
pip3 install --upgrade
– If updating doesn’t work or isn’t applicable, consider downgrading Python to a version where `unescape` is still available (e.g., 3.8 or earlier). However, note that this isn’t the best approach as you won’t benefit from new features and improvements coming to Python 3.9.
– Another option would be to edit the troublesome package’s source code directly. This is typically the least desirable solution, as it involves modifying third-party code which could lead to other unexpected issues.
Looking forward, the way to prevent such situations is by always monitoring for deprecation notices. When a feature gets deprecated, it signals that it will be removed in future releases. As a result, developers should look for alternative features or methodologies suggested by the language maintainers. Doing so ensures your code remains compatible with newer versions of the programming language, and reduces the chances of encountering compatibility obstacles.
Remember, software development is dynamic. Keeping up-to-date with changes, although occasionally demanding, ultimately leads to better and more reliable software systems.If you’re using
pip3
on Python 3.9 and you’ve encountered the error message stating that the “HTMLParser object has no attribute ‘unescape'”, it’s likely due to a compatibility issue related to changes in Python’s HTML Parser.
To understand why this error occurs, you need to delve a bit into Python internals. The `html.parser.HTMLParser` object had an `unescape` method which was deprecated since Python 3.4 because of insufficient support for entity references. Following its deprecation, it was entirely removed in Python 3.9 source.
Among the effective strategies to circumvent or fix the “
HTMLParser object has no attribute 'unescape'
” error, you can consider three approaches:
Using an Alternate Unescaping Method
You could replace the missing functionality with the html.unescape() function from Python’s built-in HTML module, like so:
import html
s = html.unescape(s)
This method is more reliable as it addresses named character references including the ones defined in HTML 5.
Downgrading Python Version
If changing the code isn’t feasible for some reason, you could consider using an older version of Python that still supports the `unescape` method. However, keep keen that older versions may lack other features and improvements present in Python 3.9.
Sometimes, the maintainers of the package that gives you trouble might have already fixed the problem, but you might not have updated your installed package yet. Use pip’s list command to check:
pip3 list
And then update accordingly:
pip3 install --upgrade <your-package>
In other cases, the latest package may not be compatible with your environment, and you might require an earlier version. Use pip to install a specific version:
pip3 install <your-package>==X.Y.Z
Remember, when dealing with errors, search engines are your best friend: try copying and pasting the error message into your favorite one. Chances are someone else has faced the same issue, and their solution (or the journey to find one) might prove immensely helpful to you.While working with Python’s Htmlparser, you might confront an attribute error that says “Htmlparser object has no attribute unescape”. This issue generally arises in the context of using pip3 on Python 3.9. A standard explanation for this issue is the possible deprecation or completely unsupported nature of “unescape” in the Htmlparser module.
Why does this happen?
import html.parser
h = html.parser.HTMLParser()
print(h.unescape('Hello world!'))
This piece of code can return an attribute error because the method ‘unescape’ was deprecated starting from Python 3.4 and finally removed in Python 3.9. Thus, if you’re using a newer version of Python like 3.9, calls to the HTMLParser’s unescape() function will fail.
The main implication of unsupported attributes like this one in Htmlparser objects is that they might cause unexpected application errors on trying to parse and manipulate HTML data, which, in turn, can lead to a gap in modern web development practices, as parsing and manipulating html data forms a crucial part of it.
As an alternative, we can use html.unescape()
Take a look at the following example:
import html
print(html.unescape('Hello World!'))
This updated piece of Python code uses the html module instead of the html.parser module to unescape characters, thus avoiding the attribute error. The result would be an output displaying ‘Hello World!’, indicating the successful implementation of the workaround.
For other potential issues that arise due to deprecated or unsupported features, consider these best practices:
Always keep your Python environments up-to-date. As bug fixes and improvements are frequently released, you stand a chance of avoiding known issues.
Make use of well-maintained libraries and APIs. These usually have active communities around them, providing quick solutions to recently introduced problems.
Be cautious when upgrading the Python environment or its packages and be ready for possible breakages in your applications. If not carefully managed, unsupported attributes can prevent certain functionalities from working.
Mentioned problems and respective solutions demonstrate just how volatile coding tools can be, making it critical for individuals and companies to be informed about updates. For additional support, refer to platforms such as Stack Overflow, where questions and answers provided by a vibrant community can accelerate troubleshooting.
If you’re using Python 3.9 and pip3, you might be experiencing a common issue where HTMLParser object does not have an attribute ‘unescape’. This typically happens when trying to install or update packages. One of the underlying reasons for this issue is that the ‘unescape’ method from ‘html.parser.HTMLParser’ has been deprecated since Python 3.4 and completely removed in the Python 3.9 version source
Prior to Python 3.9, ‘unescape’ would convert a string containing HTML character references to characters. Now with Python 3.9, anyone still relying on this method can face issues while attempting to use pip3.
But don’t worry, there are alternative methods you can choose from for replacing this deprecated ‘HTMLparser’ functionality:
Using html.unescape()
A direct replacement of ‘HTMLParser.unescape()’ is ‘html.unescape()’. Introduced in Python 3.4, it works just like its predecessor, by converting HTML encoded text to a standard string representation.
import html
s = "<hello world>"
print(html.unescape(s)) # Outputs:
Using xml.sax.saxutils.unescape()
If your application also requires handling of XML entity references, then ‘xml.sax.saxutils.unescape()’ can be used. However as it primarily designed for XML, not every HTML encoded text will handled correctly.
from xml.sax.saxutils import unescape
s = "hello & world"
print(unescape(s)) # Outputs: "hello & world"
In the case of pip3 on Python3.9 failing due to ‘HTMLParser’ object lacking an ‘unescape’ attribute, the problem lies with some dependencies that still try to use HTMLParser.unescape(). The trouble here lies within the distribution packages given the fact they haven’t adjusted their code to conform to the changes implemented in Python’s newer versions.
One concrete solution for this would be to modify the package code manually, swapping instances of ‘HTMLParser.unescape()’ with either ‘html.unescape()’ or ‘xml.sax.saxutils.unescape()’, depending upon preference and requirement. While this may involve slight complication as the user has to locate the error raising points and rewrite code sections accordingly, only such an approach actually addresses the root of the problem.
Alternatively, until these packages update their codebase to support Python 3.9, a workaround would be to downgrade Python to an older version that supports ‘HTMLParser.unescape()’ such as Python 3.8 or lower.
As every choice brings along pros and cons, pick an option wisely considering both your skillsets and project prerequisites. If you opt for the temporary workarounds, remember to upgrade promptly once the packages update following their remediation measures.
The issue you’re facing is likely related to changes made from Python 3.4 onwards, with the deprecation of `HTMLParser.unescape()`, which was completely removed in Python 3.9. This can indeed cause issues with backward compatibility when working on older projects or using older libraries that have not been updated. It’s important to consider the steps towards addressing backward incompatible changes when a new Python version is introduced.
Our main focus here is on the specific error:
AttributeError: 'HTMLParser' object has no attribute 'unescape'
This error occurs when the pip3 function tries to utilize the `unescape()` method, which no longer exists in Python 3.9. But let’s take a closer look into this issue and craft an approach to handle it.
To fix this issue, there are two promising strategies:
* Substitute ‘html.unescape()’ where ‘HTMLParser().unescape()’ was formerly applied
* Work in a Python environment older than Python 3.9, specifically Python 3.7 or 3.8
Substitute ‘html.unescape()’
Switching from `HTMLParser().unescape()` to `html.unescape()` might be the most straightforward and robust solution. Whereas `HTMLParser` was an object with multiple methods, `html` is a module with various functions or methods.
Here’s an example of how to make the switch:
Instead of writing this:
from HTMLParser import HTMLParser
h = HTMLParser()
print(h.unescape('|'))
You would change it to this:
import html
print(html.unescape('|'))
However, remember that updating the code this way will only work if you have control over the code. If there are several instances of `HTMLParser().unescape()`, replacing each occurrence manually could become quite laborious. Therefore, this approach is recommended if the instances are limited or manageable.
Work in an Older Python Environment
If you don’t maintain the code itself—perhaps it belongs to third-party packages—you also have the option of working in a Python environment that uses a Python version prior to 3.9. For instance, Python 3.7 and Python 3.8 still support `HTMLParser.unescape()`.
A virtual Python environment can be created using venv, so you can install and use an older Python version without affecting your system-wide Python setup. Here’s an example of how to make a new virtual environment using venv:
After creating and activating the environment, you can then install the necessary packages via pip3 and run your code.
It’s essential though to cautiously think about how these updates will impact your overall codebase and future development. The reasons for depricating certain functions often include security flaws or optimization issues. Hence, remaining ‘in the past’ may unintentionally infer some risks or hinder your code’s performance.
This discussion highlights how a coding language’s constant evolution keeps us as coders on our toes! However, being prepared to adjust, learning and growing along with the language’s progress, means we have the exciting opportunity to enhance and modernize the codebases we work on.After a thorough analysis, it can be deduced that the issue of Pip3 on Python3.9 failing due to Htmlparser’s missing attribute ‘unescape’ is rooted in significant changes that occurred from Python 3.4 onwards. This predicament often bewilders many developers, especially when they encounter issues while trying to install or upgrade packages using Pip3 in an environment running Python 3.9.
The solution lies in understanding that as of Python 3.4, the ‘html.unescape()’ method was introduced source. However, in older versions of the HTMLParser class, there was a method named ‘unescape’, which got deprecated in Python 3.9 source. Subsequently this leads to the error, since Pip3 tries to call the method that no longer exists.
Here’s the old usage with the deprecated ‘unescape’ method:
Seems like Pip3 scripts, unfortunately, haven’t been updated accordingly, causing these errors. To fix this, you will need to locate any script referencing the HTMLParser unescape method and modify it to use ‘html.unescape()’ instead. This helps avoid the interruption in package installations or upgrades.
This problem emphasises the importance of keeping not only our main codebase updated but also supporting scripts that might interact with newly introduced language changes. It showcases how a seemingly minute alteration in programming languages can substantially impact larger systems riding on their capabilities, thus affecting the entire software operation. It also underlines the importance for teams to regularly ensure compatibility between different components especially after major language version upgrades. Remember, updating your systems periodically can effectively prevent such problems in software development.
Gamezeen is a Zeen theme demo site. Zeen is a next generation WordPress theme. It’s powerful, beautifully designed and comes with everything you need to engage your visitors and increase conversions.